Web-based Facefilter with Speech Recognition?
The end of the year is was approaching, so everyone is preparing Christmas mailings, cards and other greetings. For our friends at Human Foundry we had something special in mind:
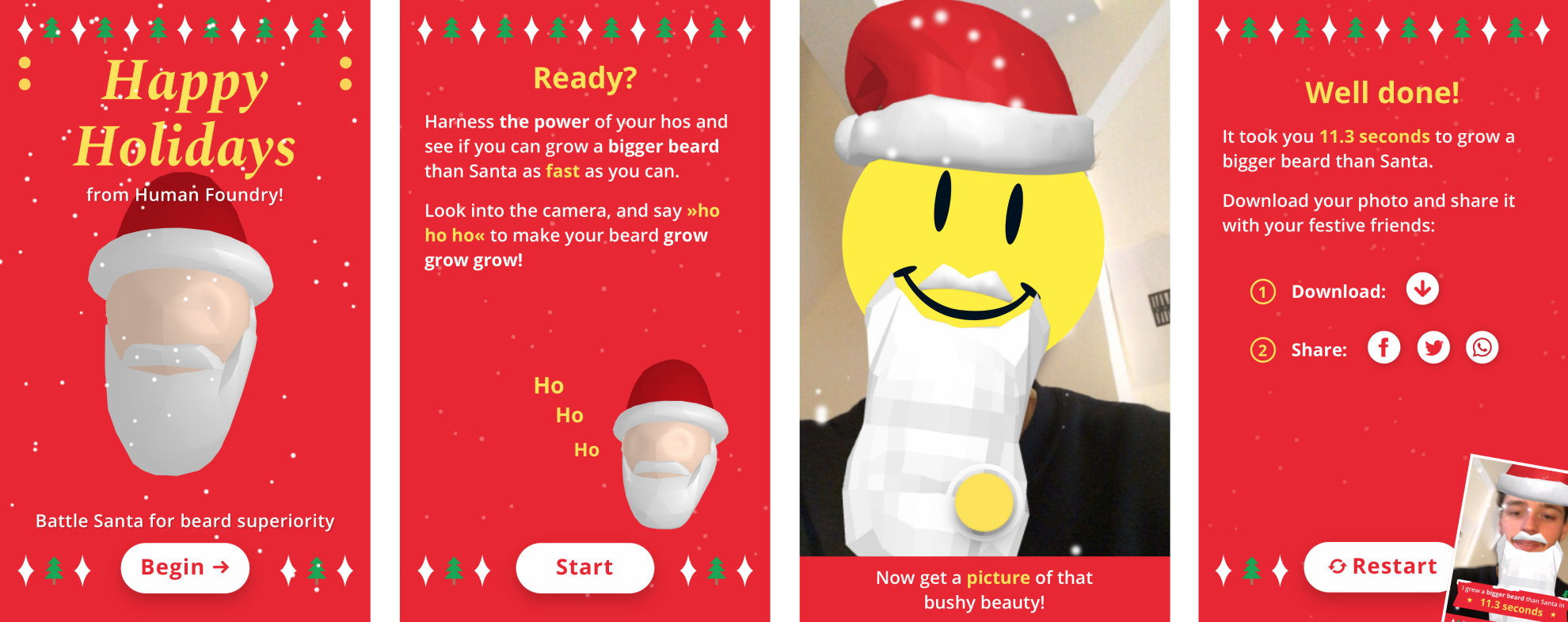
Battle Santa for Beard Superiority!
A voice controlled Face Filter where users grow a virtual beard by singing several christmassy «Ho Ho Hos». At the end of the experience, it generates a custom sharing image with the full beard and the measured time it took to make it grow.
How did we do it?
For the tracking, we used the fabulous Face Tracking Plugin from Jeeliz. They trained a couple of neural network models to map 3d elements onto faces using the native 2d camera stream and the 3d library three.js. We combined this with our own node.js speech rec implementation, added an animatable 3d beard and voilà: you get a speech recognition driven Face Filter.
Growing a 3d beard was a bit tricky, to say the least. Current web-based 3d animations work mostly by moving around a fixed amount of vertices, so called morphing. Generating and controlling new planes (the growing beard) with new vertices is not supported in the current 3d standard Gltf (although they already call it the JPEG of 3D).
After experimenting and test-exporting quite a lot of variations from Blender, we finally still went with the morphing approach. Mixing controllable morphTargets and hiding the not-yet-grown beard behind the already grown, was working best.
Each Morphtarget equals one fixed state of all vertices distributed in space. By mixing a couple of them together, we could fake a non-linear growth of the beard.
Here’s a basic step-by-step guide on doing your own:
Javascript controllable Shapekey animation
[workflow end 2018 blender 2.79]
- draw your final shape and from that all the in between shapes (make sure to not add or delete any vertices!)
- Add each in-between-shape as a shapekey to the final model: click first on step then on final model, then add shapekey with <Join as shapes>
- Export only the final model with the Kronos Gltf Exporter
- After the export interpolate between shapekeys [1,0,0] to [0.5, 0.5, 0] to [0,1,0]
Further
Speech recognition introduces a new category of Face Filters. We haven’t seen any voice controlled filters for now and can imagine a couple other fun games where the surrounding in your scene reacts to the users voice or different sounds. It could be clapping, analyzing the loudness or just generating custom filters by asking for «a policehat and googly eyes». Maybe next christmas...
Until then: try it for yourself here.
Collecting cross-device gyroscope data with lastdab.com
As we couldn’t find any online.

Live Cross-Browser Speech Recognition in Node with socket.io & Google
A Playground.
